Background Fetch API: Get Ready To Use It!
I had a section with the explainer of Background Fetch API in many of my PWA slidedecks I presented during the last 12 months. It’s in “Upcoming Features” chapter of my “Advanced Service Worker” session, and I only introduced the basic concept and had some code on the slides. The late evening before the day of my talk at HolyJS conference I decided to check the state of this promising API at ChromeStatus.com and in Chrome Canary (I love to report all the latest statuses during my sessions) and… I didn’t sleep much that night — I found the latest API spec in the almost working state and dedicated some hours to the experiments. This article is about the idea of background fetch in service workers and about how to start using it now.
Disclaimer: Background Fetch API is still very experimental. It has only the rough specification proposal and partially working implementation in Chrome Canary (M72) with Experimental Web Platform features flag enabled. All the concepts/interfaces/methods/events might change in the future.
What is Background Fetch?
If we look at the Progressive Web Apps concept from “filling the gap between web and native apps functionality” point of view, this API brings manageable and predictable downloads and uploads of the large assets (sets of assets to be precise): files, resources, you name it. Large enough to start worrying about the possible network interruptions, and/or script timeouts. For example, storing locally MP3-files of your music streaming service, or podcast episodes, or maybe even some videos, or large PDF-files.
You might say that we do it for years without any service workers — just click a link to the file and the browser will do the rest: with the possibility to pause, cancel and restore the download. You are right, but you download this resource to the operating system’s context (file system), not your web application. Everything we get from the network using Background Fetch API we can store in the context of the corresponding app for later use without any extra hassle.
Now you say that we can achieve the same by just using the fetch event of the service worker. Yes, we can download some file and put it into app origin’s Cache Storage (and this is what we normally do for the app shell architecture and runtime API endpoints caching). The differentiator here, again, is the size of this resource — is there a chance that the browser will kill the service worker during the download because of the timeout. Also, from the UX perspective, it really makes sense to notify the user about the download fact and its progress.
Background Fetch is here to solve the large assets download/upload issues in both developers and users friendly way. Let’s have a look at the features of this API listed at the WICG’s (Web Incubator Community Group) repo playing the role of specification proposal:
- Allow fetches (requests & responses) to continue even if the user closes all windows & workers to the origin.
- Allow a single job to involve many requests, as defined by the app.
- Allow the browser/OS to show UI to indicate the progress of that job, and allow the user to pause/abort.
- Allow the browser/OS to deal with poor connectivity by pausing/resuming the download.
- Allow the app to react to success/failure of the job, perhaps by caching the results.
- Allow access to background-fetched resources as they fetch.
In simple words: after we registered a background fetch and initiated the transfer by this fact (it could be done both in our main thread and in the service worker) we are fully covered by the browser (or the platform) possibilities. During the transfer, we can close the tab with application — the transfer will not stop. We can close the browser — the transfer will continue after the browser restart. The network may go down — the browser will continue the transfer automatically after it’s up. The results of the operation will be sent to the service worker (as the application tab might be closed by that time). And despite this API’s name, it’s not 100% “background” operation as it gives to the user the clear understanding about something is going on.
The feature set looks really interesting, let’s start coding to see how that works and how that looks like!
Background Fetch MVP
We start from the very minimal solution, just to check if that works at all. The plan is the following:
We register a service worker
We register a background fetch in our main app by clicking the button
We listen to the background fetch events in the service worker. On success — we put the asset(s) into Cache Storage. On fail — we still try to put into the storage all we might get
Disclaimer: to focus on our today’s topic we will not create a PWA in its full sense (there will be neither app shell nor web app manifest), so we can formally call our project a “service worker-driven website/webapp”.
Minimal code to see the download starts
The code for Step 1 is below:
On the app start, we register a service worker file service-worker.js. Please note that even for this demo I use the best practices for the registration to just emphasize the importance of:
Feature detection — to not break the app in older browsers. Good manners for most of the PWA features.
Registration postponing until window.onload. Well, in our case we don’t have any other resources to load except index.html itself, but let this proper registration snippet be a reminder about the fact that service worker cannot improve the first-load experience, but it can easily make it worse.
On “Store assets locally” (“_Download_” term does not 100% correctly reflect the action we perform) button click we call backgroundFetch.fetch() of the active service worker registration. It registers a background fetch and immediately initiates the transfer.
In our service worker, in addition to utility install and activate events (to simpler track the lifecycle stage), we have only one useful event handler at the moment: backgroundfetchsuccess where we output the registration object of the event. Let’s see it in action! For our example, I download 1,39 GB movie file (to have some seconds to watch the flow) from the same origin using http-server static webserver on Mac OS. (A reminder: we have to use Chrome Canary M72 to test Background Fetch API)
 We download the file using Background Fetch API
We download the file using Background Fetch API
Yes! It works! We see our file downloading in the browser’s bottom bar (where we normally see the regular downloads). So what happens if:
You close the tab with the app: download will continue, you see it in the bottom bar.
You close the browser (by clicking x button): the closing confirmation will appear. If we confirm — the download will still continue, now the status is on the browser’s icon:
 Chrome is downloading the asset without the window open
Chrome is downloading the asset without the window open
- You unload the browser from the memory (by choosing Quit from the right-click menu): download will stop but will continue after you launch the browser again.
Awesome! We have a download mechanism which is persistent across the app status and browser restarts. We can even Pause/Cancel this transfer:
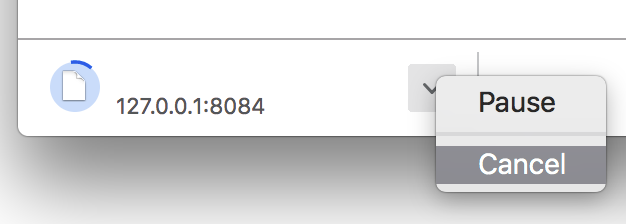 Using standard browser download UI to manage background fetches
Using standard browser download UI to manage background fetches
There is only one issue: we download this asset to… nowhere! Because it’s up to us — what do we want to do with these bytes received. Time to implement it!
The code to store the received data in the Cache Storage
We take the sample code from Background Fetch API proposal repo in the simplified form for now. At the same time in our main app let’s add the second asset to download to the same registration of the background fetch — it’s possible according to the spec.
Let’s split it into steps:
Button click in index.html: we register a background fetch with the ID my-fetch and the array with two files as a target. We can pass the array of URLs (this is what we do) or Requests (useful for upload usecase) there. Right after the browser starts executing this request (download).
Download ready in service-worker.js: service worker gets backgroundfetchsuccess event where we:
Open (or create) the cache with the name equals background fetch registration.id. The cache name could be any string actually.
Get all the records of this background fetch using registration.matchAll(). Each record = URL/Request we listed during background fetch registration.
Build the array of promises by iterating through the records, waiting until record’s responseReady resolved and trying to put this record’s response into the Cache Storage.
Execute the promises
The result:
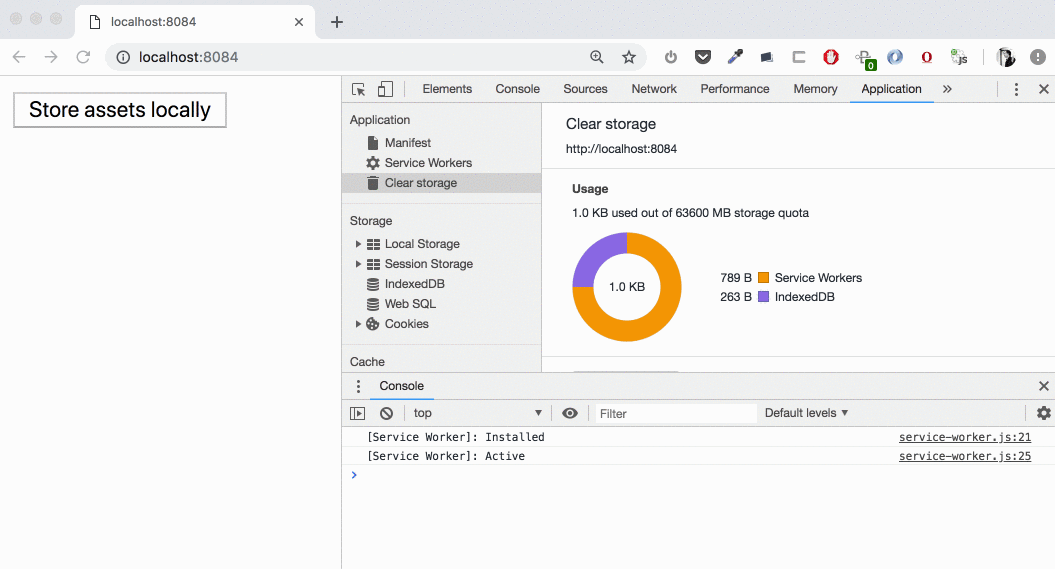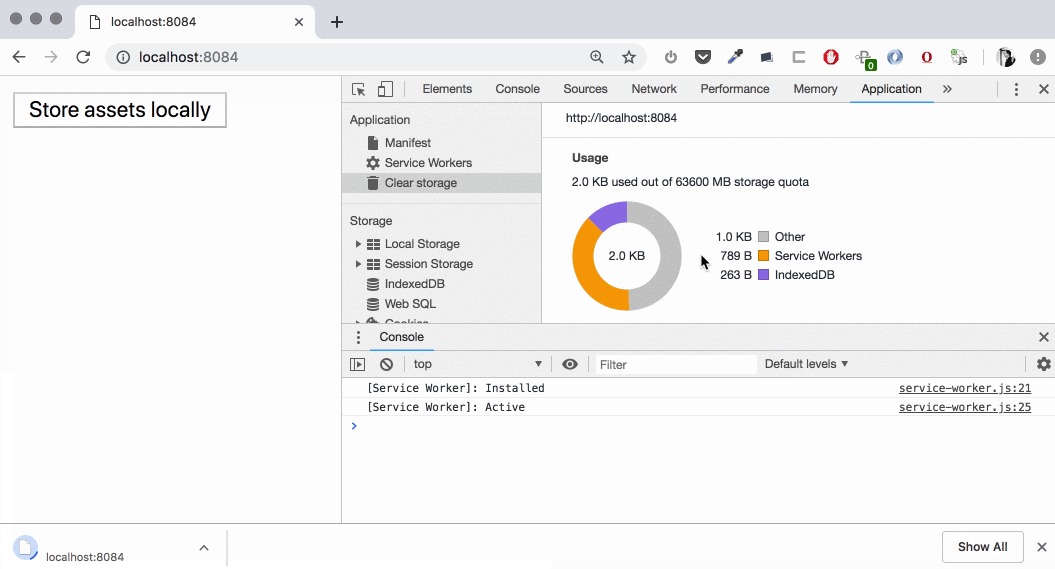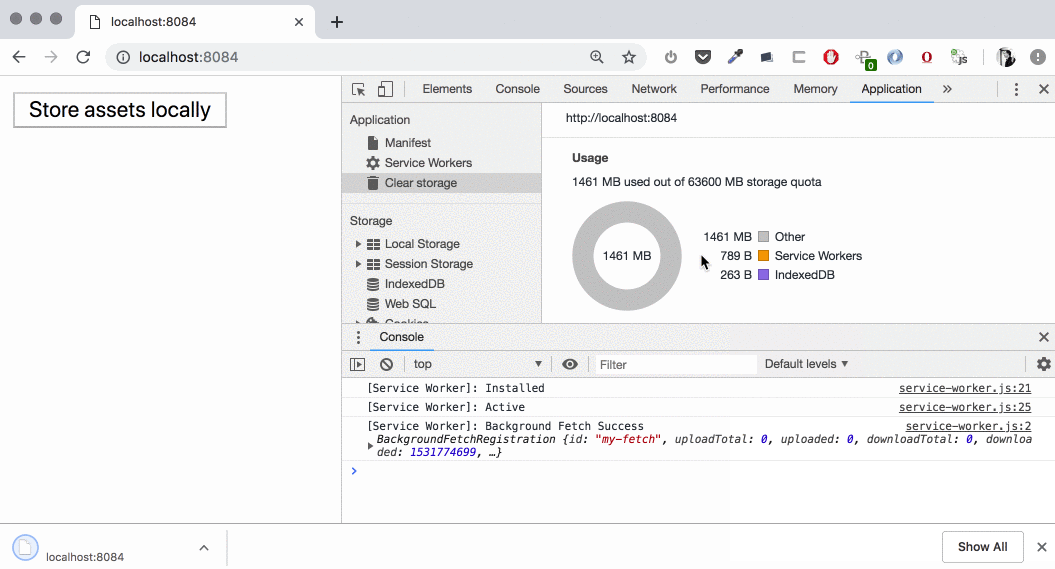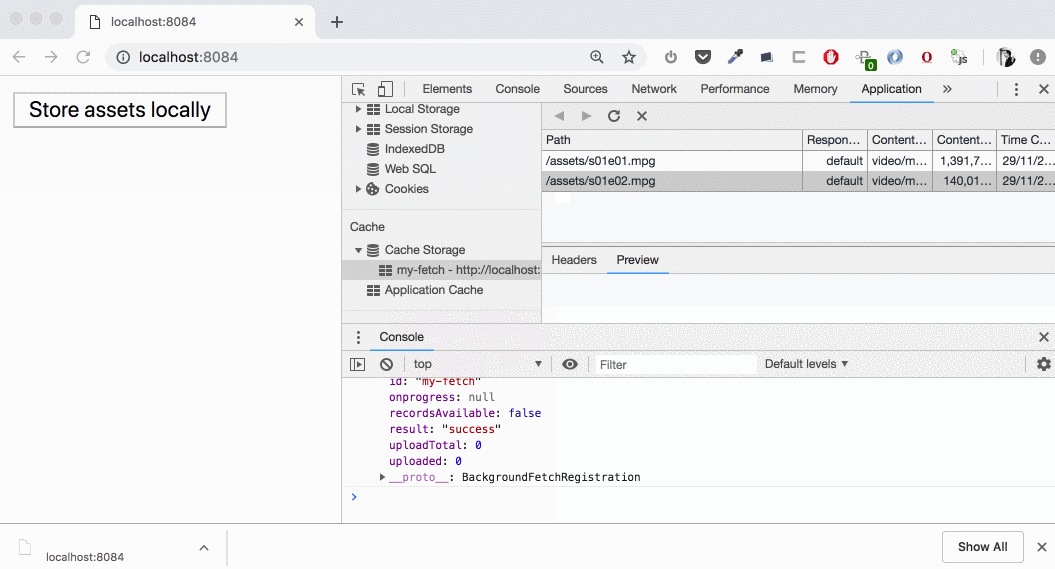 Downloading two large files
Downloading two large files
We see how the downloading is beginning and “Usage” chart is updating. During the download time we have our data in “Other” category, then (on cache.put()) it’s moving to the cache. If we open “Cache Storage” section we’ll find these two large files (1,39 GB and 140 MB) there — now we can intercept the requests to these and serve them from the cache!
There is another thing. According to the specification, the browser should show the “Download multiple files” confirmation dialogue like this:
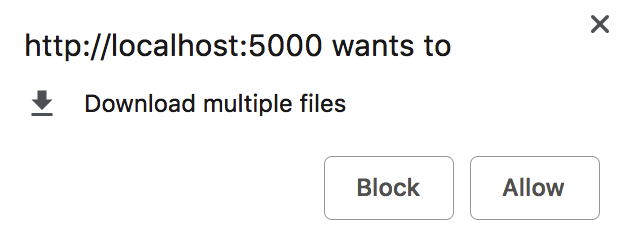 Native confirmation dialogue
Native confirmation dialogue
Sometimes it shows up but most of the times it’s not there. I tried to change the origins, reset cache, use different assets in the background fetch registration but was still unable to reproduce the sustainable popping up of this window. Most likely it’s the bug of the current Chrome Canary build. Anyway, I can explain how that works: if you click “Block” you change the setting for “Automatic downloads” for this origin and you see the corresponding icon in the address bar:

This is why we have the alert() with the explanation of how to fix this in the catch block of background fetch registration. Most likely the possible error’s cause is exactly this setting.
The last comment related to the code. Why do we disable the “Store assets locally” button if the background fetch registration was successful? To avoid another possible error: double registrations with the same ID. If the first registration is active (performing the network transfers) the second registration with the same ID will be rejected. After the transfer completion, the corresponding background fetch registration to be removed and we can enable the button (not implemented at this moment) if we wish to give the possibility to perform exactly the same operation like the just completed one.
Some observations:
The transfer appears neither in DevTools -> Network tab nor Downloads section of Chrome Canary. In that sense, it’s 100% true background fetch.
Turning on “Offline” checkbox in DevTools -> Network tab doesn’t affect the transfer.
Resuming of the download after unloading the browser from the memory works weird. The transfer starts again but the flow stops after every status change: after downloading the first file you have to restart the browser to start downloading the second. After downloading the second file you have to restart the browser to call backgroundfetchsuccess event. I hope this will be fixed in the release version.
So almost all works good but looks not very user-friendly: not very informative to be precise. Let’s use the possibility to provide some meta-information about assets and to track the progress.
Organizing a better UX
Let’s externalize the JSON with meta-information about the asset set we want to register and add some extra features to our main app and service worker:
What was added:
JSON file with some settings (meta-information about this asset set). We fetch this data both in the main app and service worker. In real life, this could be a call to your backend API — to get the settings of this specific asset set based on its ID (hardcoded as 'series’ in our code).
index.html: we now pass the options optional parameter to the background fetch registration containing thetitle, icons, downloadTotal — pretty much self-explanatory properties. Also, we attach progress event listener to the background fetch registration where we have an access to downloaded property which is changing with some periodicity.
service-worker.js: both on success and failure of the main operation we update the download indicator with the current status and the title of the background fetch we specified in JSON settings file. Of course, instead of this optional title property we could use background fetch registration ID both for the main app and service worker messages, but this ID is not for the UI (it can be a long auto-generated unique hash-string for example), so it’s a really good idea to have the human-friendly title provided.
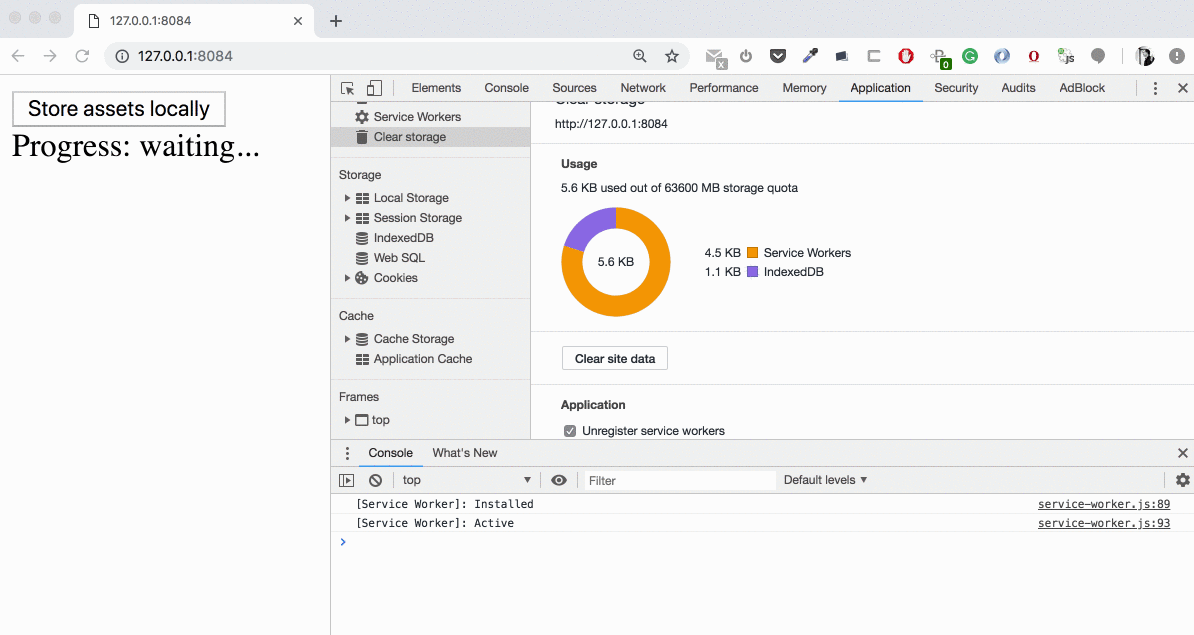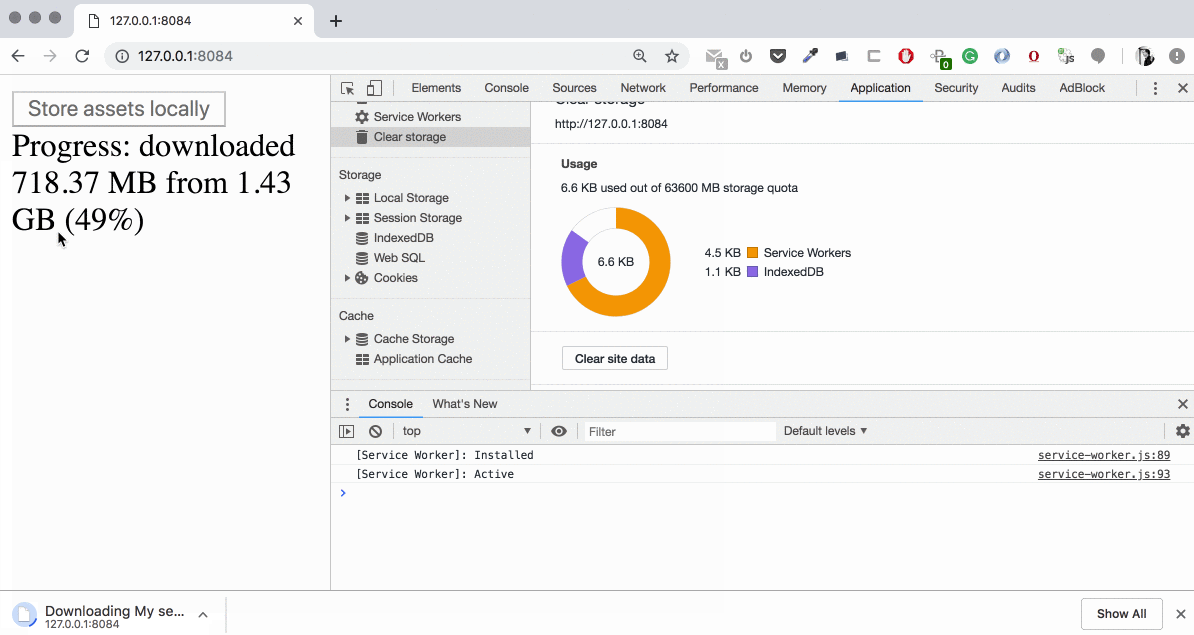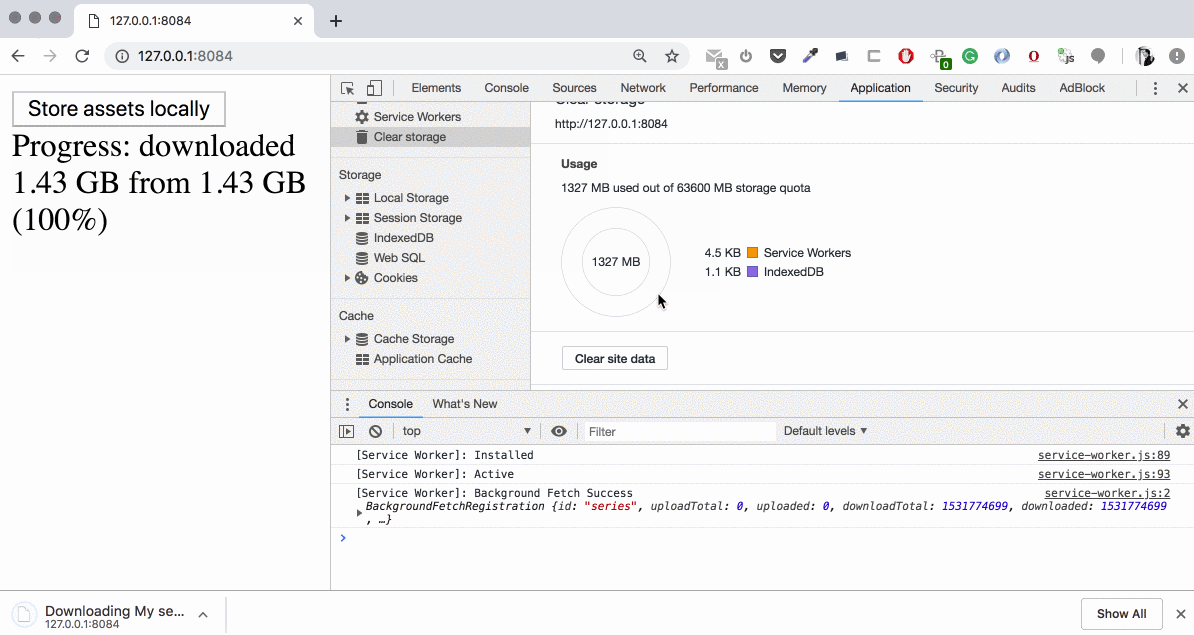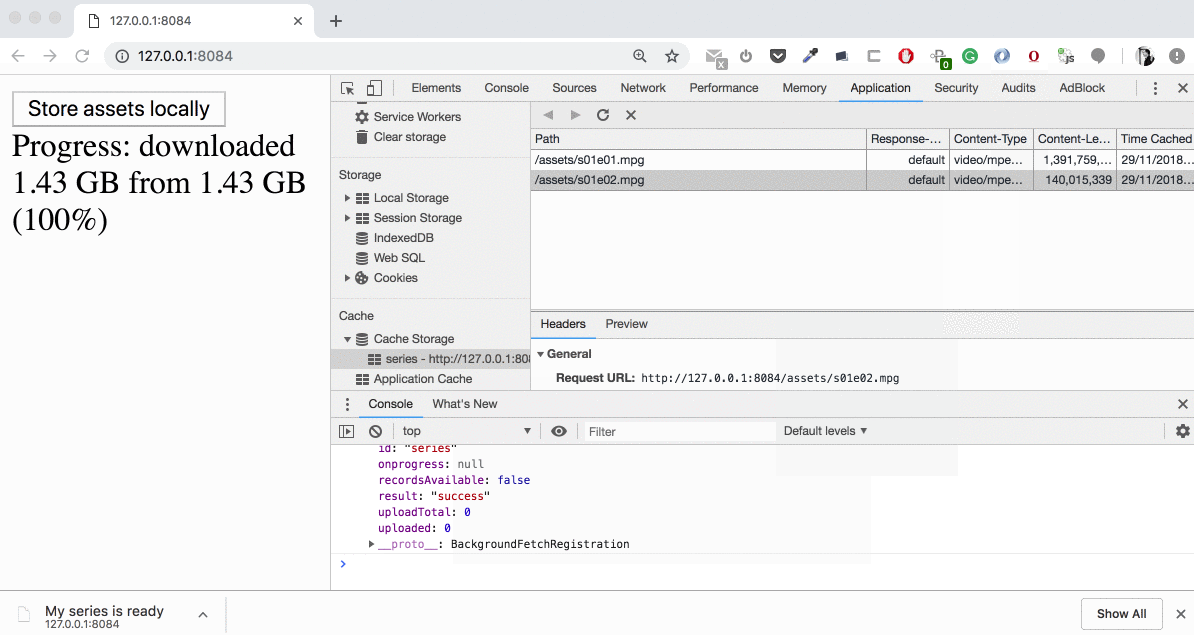
Now we have a full control over the texts and user informing. Some notices:
I was unable to make the custom icons showing up. Maybe this feature was not implemented yet or I use the wrong object format.
The downloadTotal property we pass during the background fetch registration is the total number of bytes of the whole set. It’s also optional. If passed, it works as a guard — we’ll get backgroundfetcherror event in the service worker if the total size of the resources is larger. Also, it’s a good helper for our UI to show the correct download percentage if needed. Unfortunately, there is another bug: at least on Mac OS this number can’t be larger than 2147483647 (2 GB) which is the maximum size of one file in the file system but it’s intended to be the maximum total size of the whole set. I’m going to submit a bug to the Chromium Bug Tracker about this. Meanwhile, if the total set size doesn’t bypass 2GB (like in our case) our calculations are correct.
Now, let’s add some more useful handlers to our service worker and experiment with some non-standard cases to call some errors.
Handling errors
We had a look only at best scenarios so far when everything works as planned which is not always the case when we deal with network connections. Let’s add more handlers to our service worker to be ready to the variety of possible errors. Again, we’ll use the code from Background Fetch API proposal repo as a foundation.
What do we expect:
On any kind of failure — let’s try to save to the cache at least what we already downloaded (and let1s tey to continue with the next asset if any)
If the user aborts the transfer — we do not store what was potentially downloaded
_Not related to the errors bu useful handler _— if user click on this transfer infobar we just open the new tab with URL we specified in our JSON file with the asset settings
Demo time! Let’s specify the wrong URL for one of the assets in our set: assets/s01e01.avi (not .mpg):
The background fetch ends up by thebackgroundfetchfail event with the registration.failureReason equal to “_bad-status_”. It’s important that despite the error with a particular asset, we continue our batch with the next asset and have the possibility to cache all our previous successful responses.
My other tries to call different types of errors:
Downloading asset from another origin. It works normally if CORS set up. If not — we end up with backgroundfetchfail event with “_fetch-error_” as registration.failureReason. You can only specify HTTPS-driven origins (or localhost).
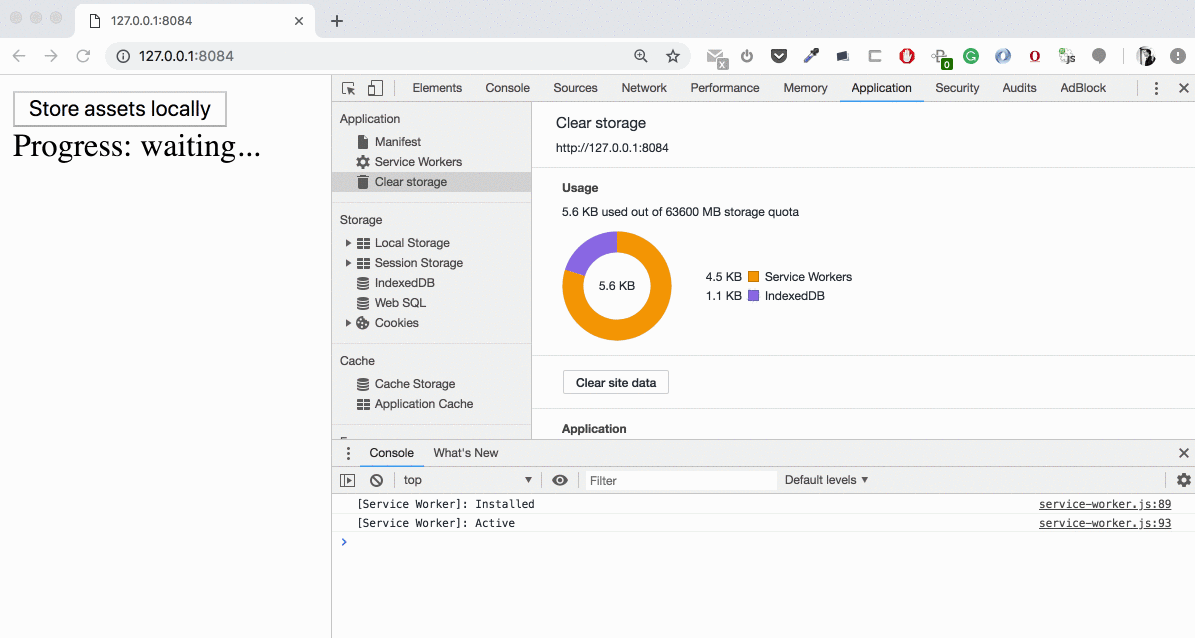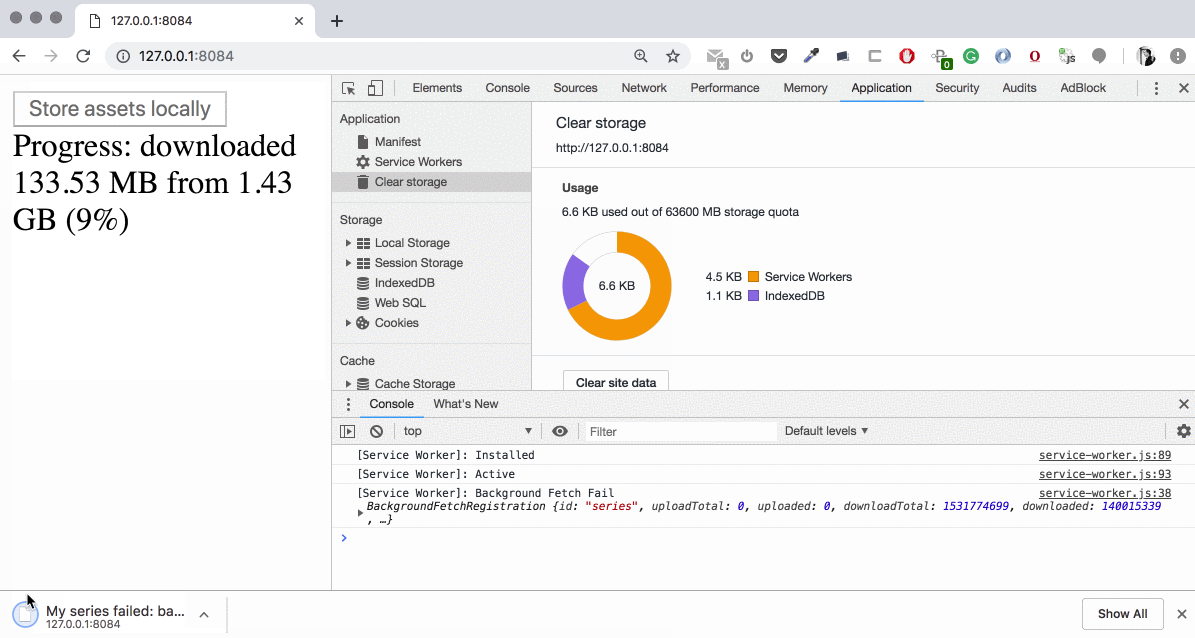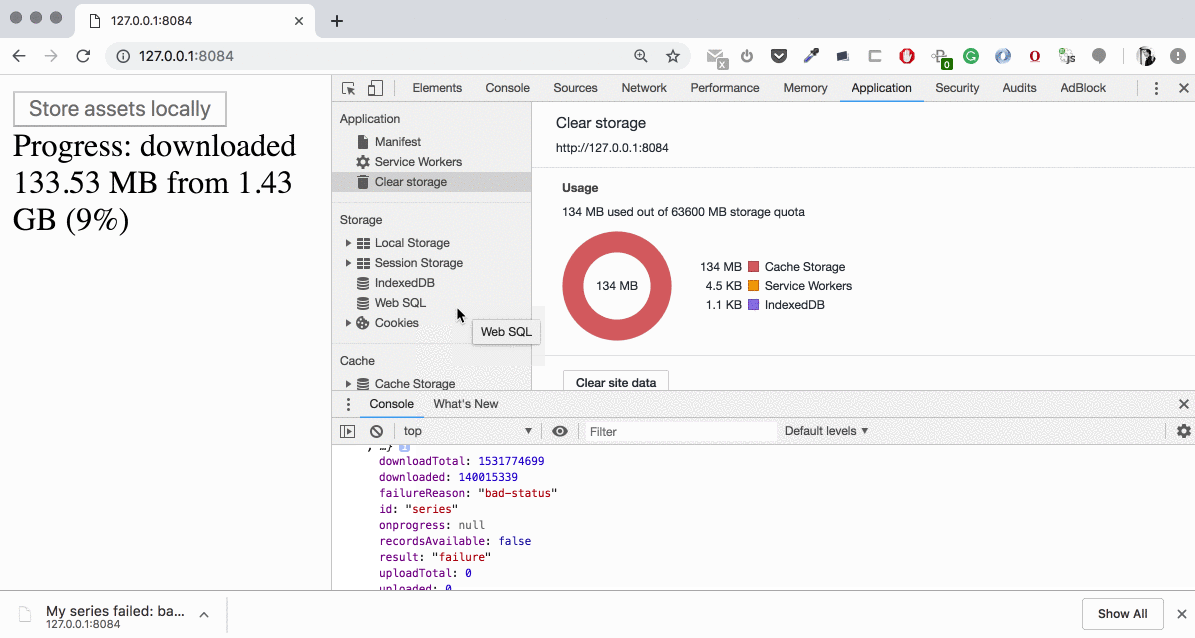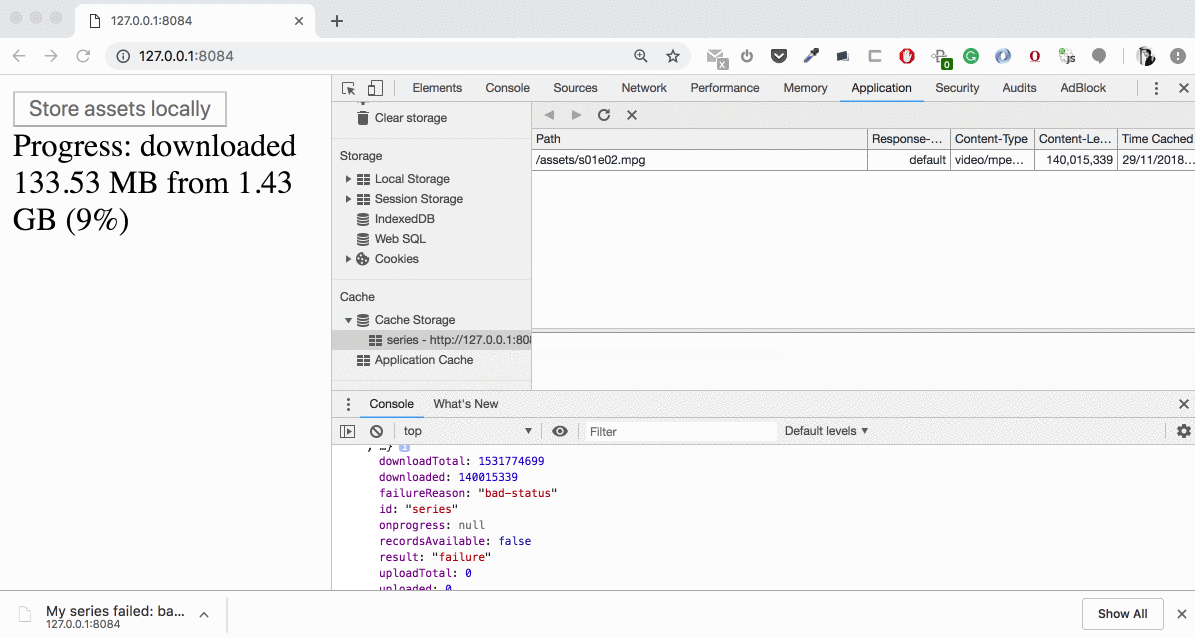
Shutting down the server and waiting until the network timeout— “_bad-status_”
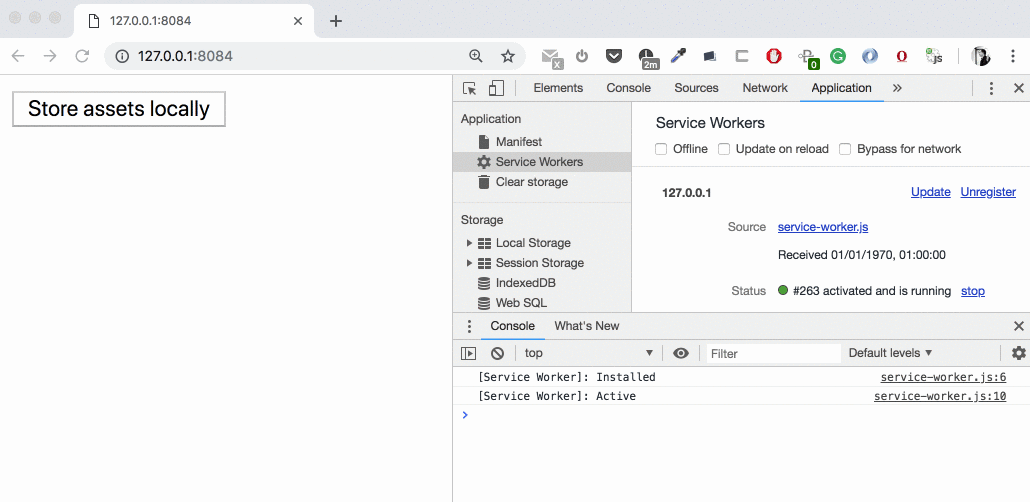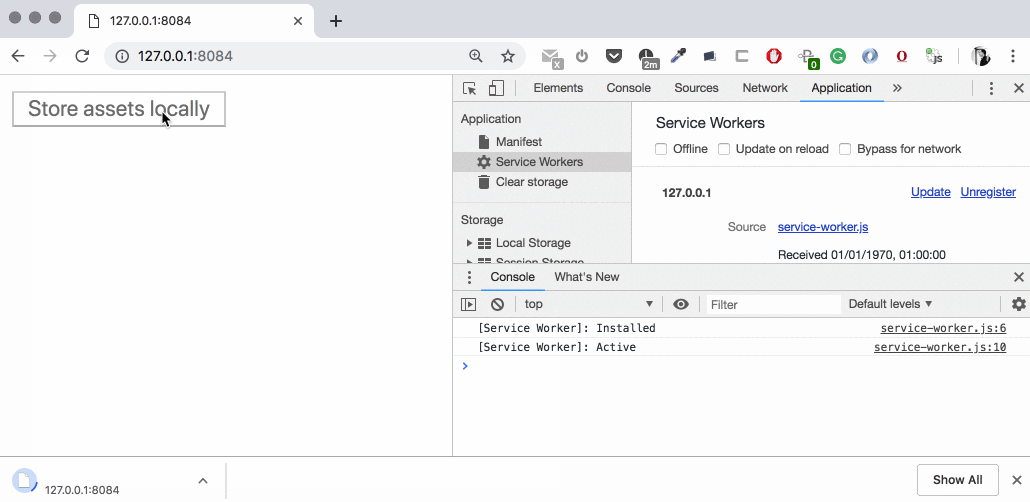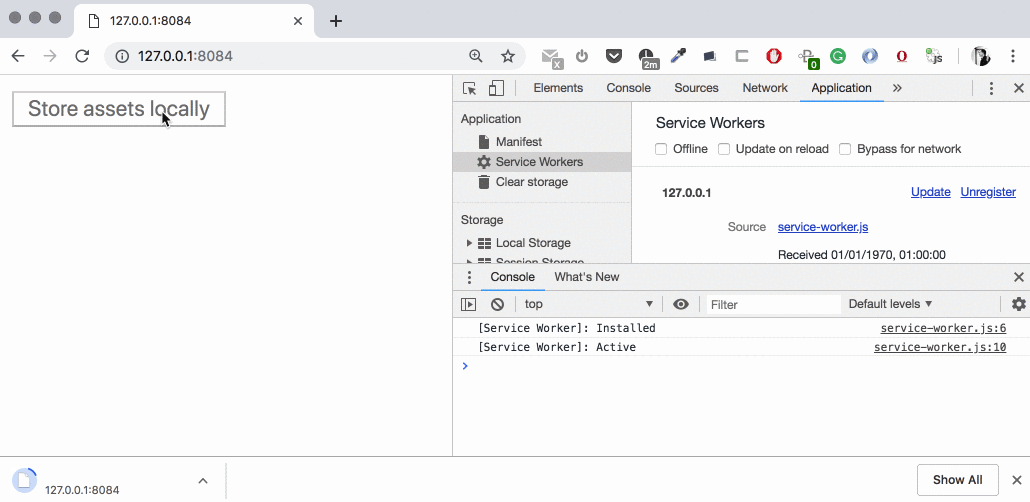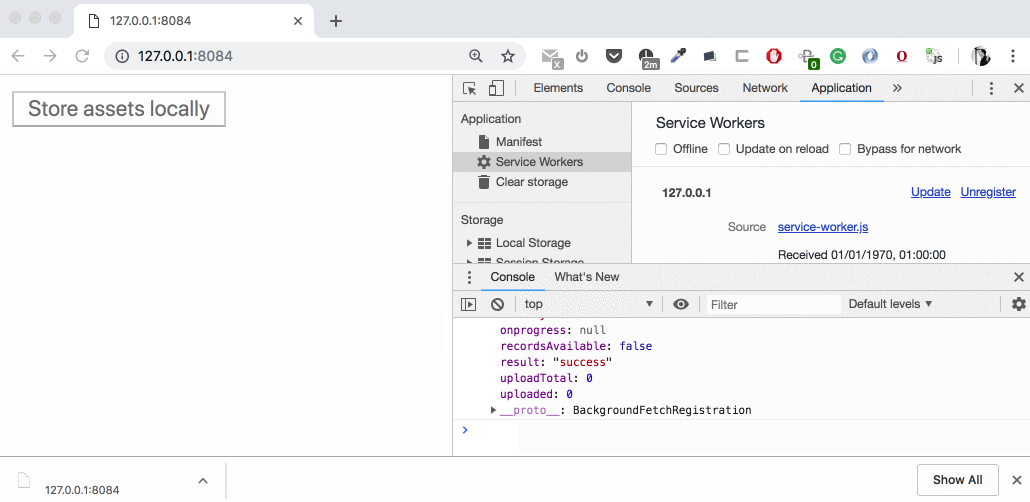
Shutting server down and starting up again (to mimic the temporarily out-of-service) — doesn’t work well. It resumes the transfer after server goes online but sends backgroundfetchfail with “_bad-status_” very soon. Also, we have non-consistent quota usage numbers:
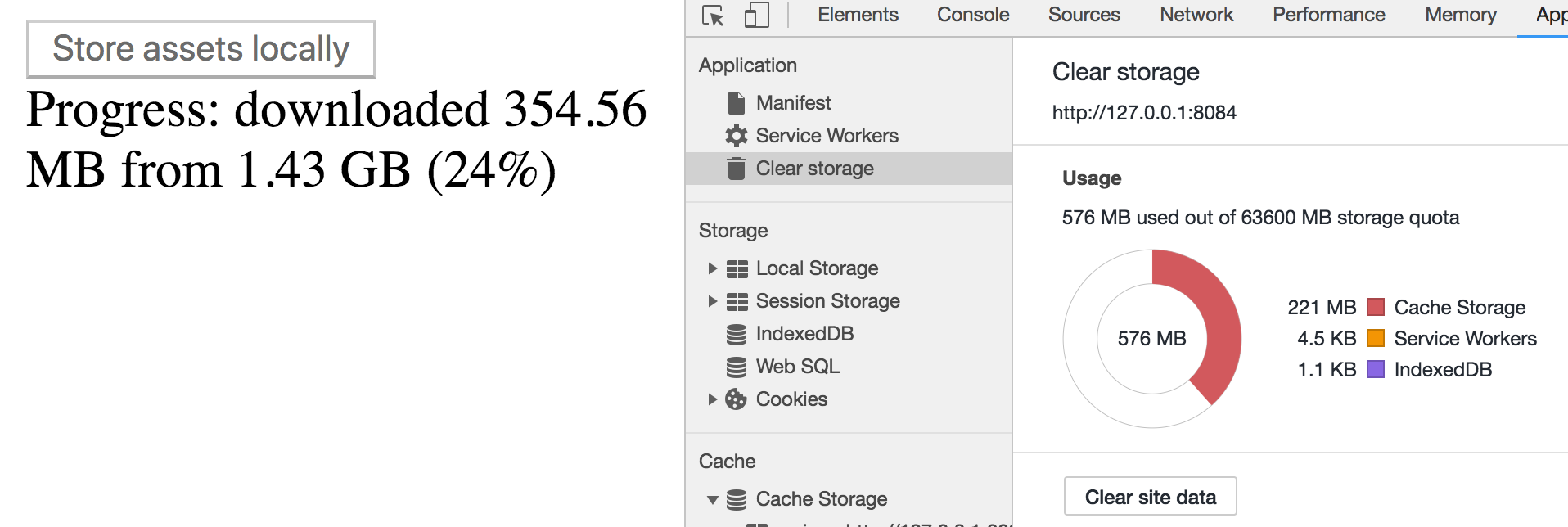 Three different values for what has been downloaded
Three different values for what has been downloaded
- Two more issues in that scenario. First, the downloading of the second file doesn’t even start (despite the server is alive). And second, “_Content-Length_” shown in Cache explorer confusingly equals to the full file size despite we were able to download this asset only partially:
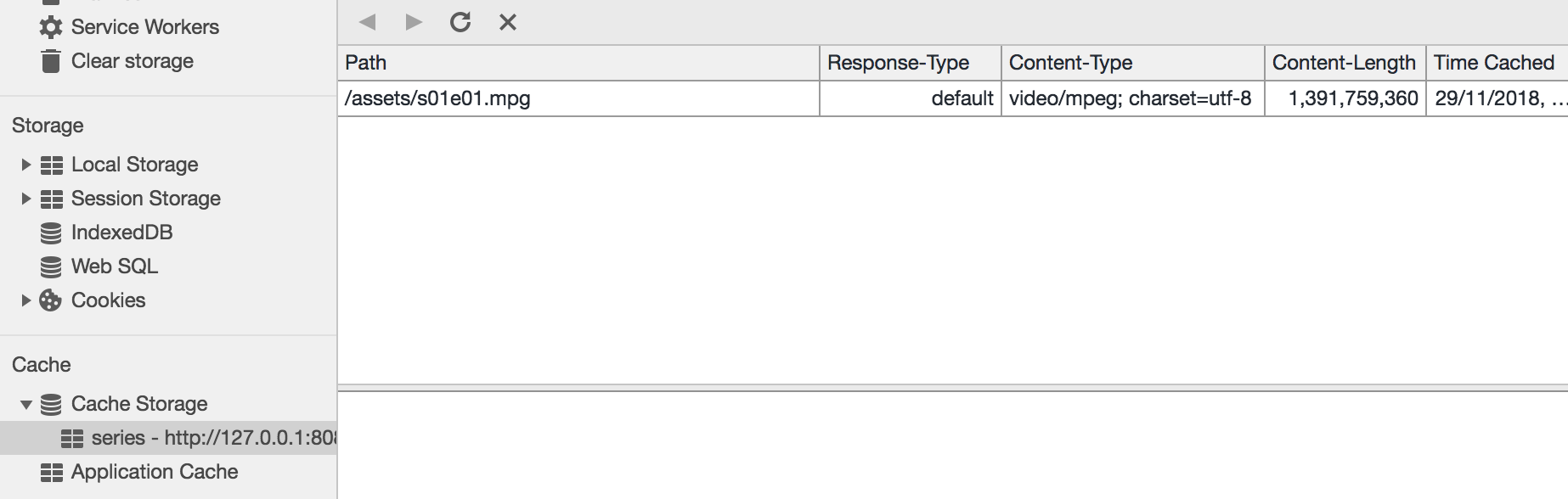 And value number four…
And value number four…
The above errors give us a chance to cache what could be downloaded successfully. According to the specification proposal, the behavior is different for the errors related to the downloadTotal property. Let’s set it equal to 140015339 — exact size in bytes of our “small” asset (s01e02.mpg). After the transfer start, we receive backgroundfetchfail with “total-download-exceeded_”. This is expected — the _s01e01.mpg is larger than this limit. What we don’t expect (but it’s correct according to the spec) — is that even s01e02.mpg will not be cached in that case — the transfer operation aborts immediately on “total-download-exceeded_” error. We can’t put into the cache even properly sized assets. So if we remove this “incorrect size”-file from the URL array to fetch, _s01e02.mpg will land in Cache Storage.
The last handler in our service worker — backgroundfetchclick — is not related to the error handling. This is what happens when the user clicks on this download infobar. In our example, we open a new tab with the URL we provided in the configuration.
The full code of the demo (with downloading images instead of large movie files) is available:
Conclusion
In my opinion, Background Fetch API could be the “next big thing” for the PWA concept. There are plenty of interesting usecases making the web apps as powerful as the native ones in terms of large app assets network manipulations. But there are some risks:
Browser vendors adoption. Yes, we all know that everything in PWA is based on “_progressive enhancement_” idea and we HAVE TO architect our apps in that way and build our apps actively using feature detection. But I really don’t want to have some APIs specific to this or that vendor.
User protection. Wasteful network traffic consumption, littering storage by abandoned resources, breaking the privacy by exposing the list of downloaded URLs are my main concerns. Downloading and storing large resources should be taken very seriously both by specification authors and developers.
I don’t want to finish this article by the “risks” statement so let me give you an idea of the module/library/package for the automation of background fetches flows. Let’s assume that we want to give the possibility to our users to store locally some set) of the static files (MP3s?) we have on our server.
Using some kind of build helper we generate background fetch manifest (looking like the JSON setting file we used for the demo). It could be the script iterating through the folders.
In our app UI, we can now generate the lists of assets. Like the filename + “Store locally” button.
We agree on some kind of API — like “on click Store locally button we POST the filename to /storage-manager endpoint”. Another endpoint for removal.
Also during this list generation, it makes sense to check the status of this asset in Cache Storage. If it’s there — we have “Remove from device” button instead of “Store”.
In our service worker, based on the background fetch manifest and API we’ve just architected above, we generate the routing for “fetch” event. Now we can register background fetches in our service worker after the request from app.
If you wish to implement it as a standalone helper or as a plugin to Workbox — ping me, I’ll give you more details about this idea.
And let’s start our experiments with Background Fetch API!
About me
I’m deep into PWA topic. And go deeper day-by-day :) I call myself PWAdvocate because I support the developers (as a developer myself) by providing the latest updates on this topic, by introducing and sharing developer-friendly and user-friendly ways to build the apps, by answering the questions. You can see me speaking and training at many conferences (I have 100+ flights each year) — please come to chat with me about PWA, Web Platform, developer communities!
Also, I’m open for the invitations to speak/train at your conference or private corporate meeting/bootcamp/hackaton in 2019— just DM me on Twitter.